python pymysql批量插入数据
python mysql批量插入数据
从mysqldump导出来的数据,都以一条sql语句插入几千条数据,导入执行时,执行一条速度均在零点几秒 速度快的飞起。
受此启发研究了一下使用 pymysql 往mysql快速插入大量数据的方法。
原理很简单,就是构造一条插入几千条数据的sql语句,然后执行。
以下是插入1万条数据,使用executemany与优化后的时间对比
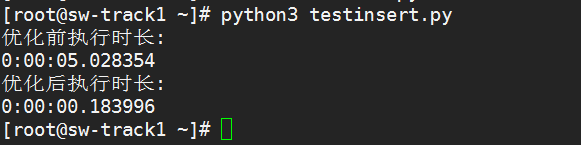
一个不到0.2秒,一个5秒多,快了将近28倍,真正实现了秒级插入万条数据
executemany看源码,其实也是一条语句插入一条数据执行的 具体这边文章有所说明
使用pymysql插入语句时对execute与executemany两个方法进行测速
- 优化前代码
test_conn.autocommit(True)
# 设置自动提交
test_cursor = test_conn.cursor()
values = []
for i in range(10000, 20000):
value = (i,'1')
values.append(value)
d1 = datetime.now()
if len(values) > 0:
test_cursor.executemany("insert into test_table values(%s, %s)", values)
# test_conn.commit()
test_cursor.close()
d2 = datetime.now()
delta = d2 - d1
print ("优化前执行时长:")
print (delta)
test_conn.close()
- 优化后代码
test_conn.autocommit(True)
test_cursor = test_conn.cursor()
values = []
for i in range(10000):
value = (i, '1')
values.append(value)
d1 = datetime.now()
count = 2000
j = len(values) // count
k = len(values) % count
for i in range(j):
start = i * count
end = (i + 1) * count
# print (start)
# print (end)
sublist = values[start:end]
valuestr = str(sublist)[1:-1]
try:
sqlstr = "insert into test_table values " + valuestr
test_cursor.execute(sqlstr)
except Exception as e:
print ('insert except %s', e.args)
test_conn.close()
return None
if k:
start = count * j
end = count * j + k
sublist = values[start:end]
valuestr = str(sublist)[1:-1]
try:
sqlstr = "insert into test_table values " + valuestr
test_cursor.execute(sqlstr)
except Exception as e:
print ('insert except %s', e.args)
test_conn.close()
return None
test_cursor.close()
d2 = datetime.now()
delta = d2 - d1
print ("优化后执行时长:")
print (delta)
test_conn.close()
这里优化的时候,一条语句插入2000条,其实也可以一条语句插入4000条 依照mysqldump导出来的语句,一条语句插入数据的数据量是2000-5000条 这边实测,从2000到4000的时间几乎一样 而且 0.18 秒,时间已经很短了,从这个代码的角度来看已经没有优化空间了 只能是数据库,操作系统或者硬件自身优化了
附上数据库表DDL
CREATE TABLE `test_table` (
`mid` int(11) NOT NULL,
`status` varchar(255) DEFAULT NULL,
PRIMARY KEY (`mid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;